
Meta Tag: X-Robots-Tag
Abbiamo già parlato in un articolo precedente dei meta tag robots, non possiamo non citare l’istruzione X-Robots-Tag
Vi è mai capitato che alcune pagine, nonostante non avessero il meta tag robots noindex, oppure non essendo bloccate dal file robots.txt, non vengano ugualmente indicizzate?
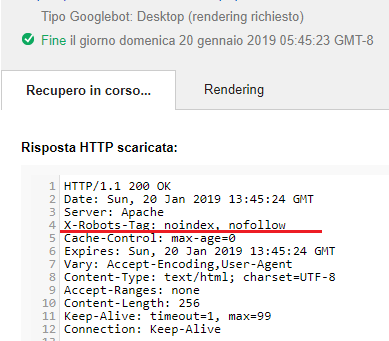
Bene una prima verifica che dovete fare è verificare la risposta contenuta nell’HEADER HTTP, ovvero la parte nascosta della comunicazione che il server restituisce quando viene richiesta una pagina web.

Nonostante questa verifica, (come nell’immagine sopra), potrebbe capitare che nella risposta non viene restituita nessuna istruzione che blocchi l’indicizzazione della pagina.
Ma allora perché la pagina non viene indicizzata da google?
La risposta è semplice. Con una semplice riga di codice, si potrebbero far restituire questi tag ” header(“X-Robots-Tag: noindex”, true); “, solo quando la pagina viene scansionata dagli spider di google (ne ho parlato, quando ho pubblicato l’articoli relativo al clocking).
In questo caso per accorgervi se questo tag è stato inserito avete varie possibilità. Una di queste è di utilizzare la funzione visualizza come google (webmaster di google)
E se la pagina non è vostra?
Potete ugualmente utilizzare la funzione visualizza come google della search console, basta inserire la pagina in un iframe, caricarla sul vostro server per effettuare la scansione
<iframe src=”https://pagina-da-scansionare-html/” width=”300″ height=”300″> </iframe>
Indice
Inserire X-Robots-Tag sezione Header
Per inserire questi tag, basta inserire una semplice riga di codice nella sezione header del file .php di un sito web.
header(“X-Robots-Tag: noindex”, true);
header(“X-Robots-Tag: noindex, nofollow”, true)
Se invece si sono file .doc, per i quali non è richiesta l’indicizzazione, sul server Apache si potrebbe aggiungere la seguente riga nel file .htaccess:
<FilesMatch “.doc$”>
Header set X-Robots-Tag “noindex, noarchive, nosnippet”
<FilesMatch”>
Mentre se non si voglio far indicizzare i file .doc e .pdf, basterebbe scrivere la seguente regola.
<FilesMatch “.(doc|pdf)$”>
Header set X-Robots-Tag “noindex, noarchive, nosnippet”
</FilesMatch>
Strumento verificare risposta contenuta nell’ header per verificare reindirizzamento
Un tool molto utile e rapido per verificare la risposta contenuta nell’HEADER HTTP è: http://www.redirect-checker.org/
Ci permette di controllare il reindirizzamento con uno specifico user-agent. Basta selezionare l’user-agent per testare il tuo reindirizzamento.